







CopyRight©2021 139GAME.COM.CN All Right Reserved
元象XVERSE-MoE-A36B开源巨献:36亿参数MoE大模型,激活AI创新新时代
时间:2025-01-01 13:04:44
编辑:
近日消息,深圳元象信息科技有限公司最新宣告,其自主研发的中国最大规模Mixture of Experts(MoE)开源模型XVERSE-MoE-A36B已成功面世。此模型的推出,象征着中国AI技术的重要飞跃,有力推动国产开源创新达到国际前沿标准。

XVERSE-MoE-A36B模型拥有255B的总参数和36B的激活参数,其性能可与超过100B参数的大模型相媲美,实现了跨级的性能跃升。该模型在训练时间上减少了30%,推理性能提升了100%,大幅降低了每token的成本,使得AI应用的低成本部署成为可能。
元象XVERSE的"高性能全家桶"系列模型已全面开源,无条件免费供商业使用,这为众多中小企业、研究者和开发者提供了更多的选择机会。MoE架构通过组合多个细分领域的专家模型,打破了传统扩展定律的局限,在扩大模型规模的同时,保持了模型性能的最大化,并降低了训练和推理的计算成本。
在多个权威评测中,元象MoE的效果显著超越了多个同类模型,包括国内千亿MoE模型Skywork-MoE、传统MoE霸主Mixtral-8x22B,以及3140亿参数的MoE开源模型Grok-1-A86B等。
元象发布全球首个大模型XVERSE-Long-256K,可免费使用
元象大模型是由深圳元象XVERSE从头训练、全链路自主研发的高性能通用大模型系列,而元象在近日发布了全球首个上下文窗口长度为256K 的开源大模型 XVERSE-Long-256K,支持输入25万汉字,无条件免费商用。
该模型填补了开源生态空白,与元象之前的大模型组成了高性能全家桶。XVERSE-Long-256K 在评测中表现出色,超越了其他长文本模型。通过算法与工程的极致优化,实现了长序列的注意力机制,使窗口长度与模型性能同步提升。
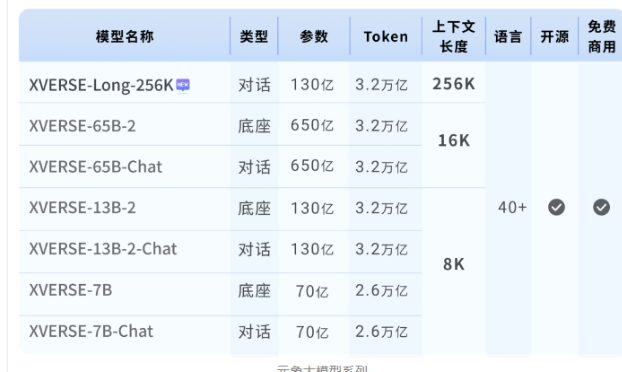
XVERSE-Long-256K 在大规模数据分析、多文档阅读理解、跨领域知识融合等方面有出色的能力,并能推动大模型应用的深层次产业落地。元象还提供了详细的手把手训练教程与技术解析,帮助用户训练长文本大模型。
用户可以在元象大模型官网或小程序中体验 XVERSE-Long-256K。